Nonlinear Dynamics as Non-Parametric Regression
Disclaimer: This material is more or less copied in whole cloth from Chapter 26 of Cosma Shalizi's fantastic Advanced Data Analysis from an Elementary Point of View. Only the model system has been changed.
As I mentioned before, many of the ideas from the nonlinear dynamics community appear very similar to ideas developed in the statistical community for the analysis of nonlinear time series1. Cosma commented briefly on using nonlinear regression for such problems in the lecture two days ago, and I thought I'd code up some examples to make sure I really understood the ideas.
First, the statistical model. The simplest regression method for time series is a linear autoregressive model: you assume the future dynamics of a system are some linear function of the past dynamics, plus noise. That is, if we denote the trajectory of our system (stochastic process) as \(\{ X_{t}\}_{t = 1}^{\infty}\), then we assume that \[ X_{t} = \alpha + \sum_{j = 1}^{p} \beta_{j} X_{t - j} + \epsilon_{t}\] where \(E\left[\epsilon_{t} | X_{t-p}^{t-1}\right] = 0\) and \(\text{Var}\left[\epsilon_{t} | X_{t-1}^{t-p}\right] = \sigma^{2},\) and we generally assume that the residuals \(\epsilon_{t}\) are uncorrelated with each other and the inputs2. For those who have taken a statistical methods course, this should look a lot of like linear regression. Hence the name linear auto (self) regression.
This methodology only works well when the linear assumptions holds. If we look at lag plots (i.e. plot \(X_{t}\) vs. \(X_{t-1}\)), we should get out a noisy line. If we don't, then the dynamics aren't linear, and we should probably be a bit more clever.
One stab at being clever is to assume an additive model for the dynamics (before, we assumed a linear additive model). That is, we can assume that the dynamics are given by \[ X_{t} = \alpha + \sum_{j = 1}^{p} f_{j}(X_{t - j}) + \epsilon_{t}\] where the \(f_{j}\) can be arbitrary functions that we'll try to learn from the data. This will capture nonlinearities, but not associations between the different lags. If we wanted to, we could include cross terms, but let's start by adding this simple nonlinearity.
It's worth noting that we've implicitly assumed that the process we're trying to model is conditionally stationary. In particular, we've assumed that the conditional mean \[E[X_{t} | X_{t - p}^{t-1}] = \alpha + \sum_{j = 1}^{p} f_{j}(X_{t - j})\] only depends on the value of \(X_{t-p}^{t-1}\), not on the time index \(t\). This assumption gets encoded by the fact that we try to learn the functions \(f_{j}\) using all of the data, and assume they don't change over time. This is a fairly weak form of stationarity (and one that doesn't get much mention), but it's also all we need to do prediction. If the process is really non-stationary, then without some reasonable model for how the process changes over time, we won't be able to do much. So be it.
Fortunately, there's already an R package, gam, for doing all of the fun optimization that makes additive models work. R is truly an amazing thing.
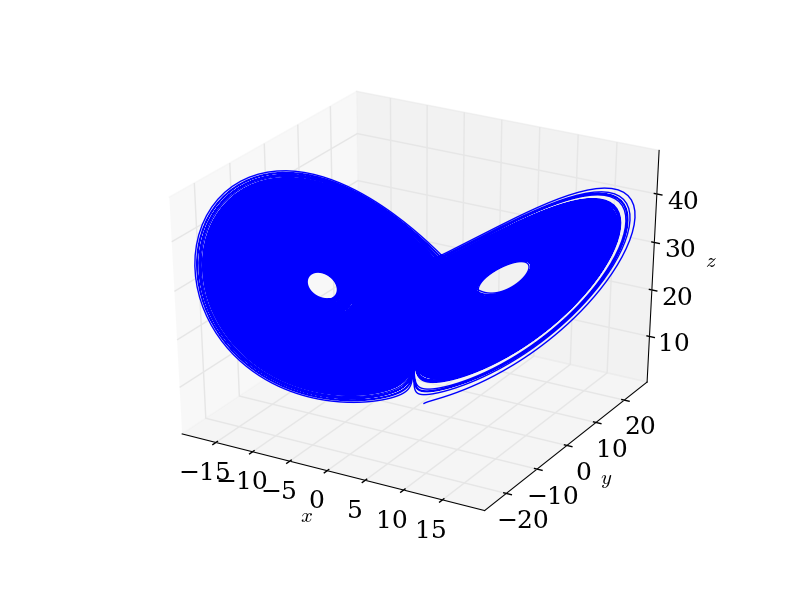
Let's use the Lorenz system as our example, \[ \begin{array}{l} x' &= \sigma (y - x)\\ y' &= x(\rho - z) - y\\ z' &= xy - \beta z \end{array}\] I generated a trajectory (without noise) from this system in the usual way, but now I'll pretend I've just been handed the time series, with no knowledge of the dynamics that created it3.
As a first step, we should plot our data:

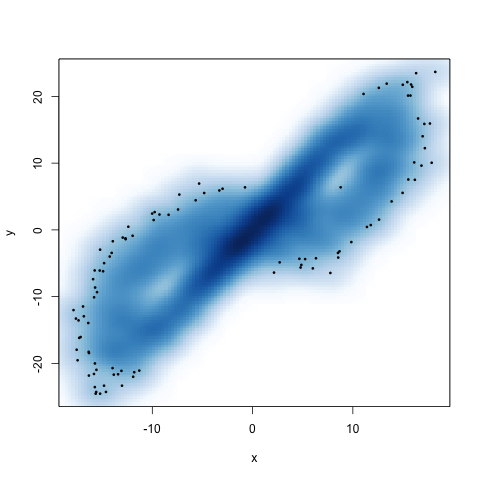
Looks like the Lorenz system. To convince ourselves that a linear autoregressive method won't work particularly well, let's look at a lag one plot:

Again, if the system were truly linear, this should look like a noisy line. It clearly doesn't (we see the attractor sneaking out). Ignore the two colored dots. The blue are the true points, the red our my estimates. But we'll get to that soon.
I'll use a order 5 autoregressive model. That is, I'll assume we're dealing with \[ X_{t} = \alpha + \sum_{j = 1}^{5} f_{j}(X_{t - j}) + \epsilon_{t}\] and try to infer the appropriate \(f_{j}\). As good statisticians / machine learners, if we really care about the predictive ability of our method, we should split our data into a training set and a testing set4. Here's how we perform on the training set:

Blue is the true trajectory. Red is our predicted trajectory. And here's how we perform on the testing set:

Not bad. Of course, we're only ever doing single-step ahead prediction. Since there really is a deterministic function mapping us from our current value to the future value (even if we can never write it down), we expect to be able to predict a single step ahead. This is, after all, what I used approximated by using an ODE solver. Let's look at the partial response functions for each of the lags:

The partial response plots play the same roles as the coefficients in a linear model5. They tell us how the new value \(X_{t}\) depends on the previous values \(X_{t-5}^{t-1}\). Clearly this relationship isn't linear. We wouldn't expect it to be for the Lorenz system.
Let's see how linear autoregressive model does. Again, let's use fifth order model, so we'll take \[ X_{t} = \alpha + \sum_{j = 1}^{5} \beta_{j} X_{t - j} + \epsilon_{t}.\]
Here's how we perform on the training set:

And on the testing set:

For full disclosure (and because numbers are nice), the mean squared error on the test set was 3.1 and 73.1 using the additive autoregressive and linear autoregressive models, respectively. Clearly the (nonlinear) additive model wins.
I should really choose the order \(p\) using something like cross-validation. For example, we see from the partial response functions that for order 5, the fifth lag is nearly flat: it doesn't seem to contribute much to our prediction. It might stand to reason that we shouldn't try to infer out that far, then. Adding unnecessary complexity to our model makes it more likely that we'll infer structure that isn't there.
With this very simple example6, we already see the power of using nonlinear methods. As Shalizi often points out, there's really no principled reason to use linear methods anymore. The world is nonlinear, and we have the technology to deal with that.
Speaking of the technology, I've posted the R code here, and the data file here. The code isn't well-commented, and is mostly adapted from Shalizi's Chapter 26. But it does give a good starting place.
As with most uses of the phrase 'nonlinear,' this one deserves some extra explanation. Here, we use nonlinear to refer to the generating equations, not the observed behavior. Just as linear differential equations give rise to nonlinear trajectories (i.e. sines and cosines, as a special case), linear difference equations give rise to nonlinear maps. Not many (any?) people care about when the observed dynamics are linear: it's easy to predict a trajectory lying on a straight line. Thus, when we say 'linear dynamics' or 'nonlinear dynamics,' we refer to the equations generating that dynamics, not the dynamics themselves. Confusing? Yes. But also unavoidable.↩
We can relax these last few assumptions and get more sophisticated models.↩
If I did have a good reason to believe I had a good model for the system, I'd be better off using a parametric model like a nonlinear variant of the Kalman filter. I've had some experience with this.↩
If I were really a good statistician, I would use cross-validation. But it's a Saturday night, and I'm already avoiding a party I should be at. So you'll have to forgive me.↩
"It's true that a set of plots for \(f_{j}\)s takes more room than a table of \(\beta_{j}\)s, but it's also nicer to look at. There are really very, very few situations when, with modern computing power, linear models are superior to additive models."↩
No offense intended towards Ed Lorenz. I mostly mean simple to implement.↩