Non-Correlation is Not Independence; with a Brief Foray into the Social Sciences
Everyone knows that correlation is not causation. But fewer people seem to remember that non-correlation is not independence1. Despite the fact I'm sure their undergraduate statistics professor rattled off, "If two random variables \(X\) and \(Y\) are independent, then \(\text{Cov}(X, Y) = 0\), but the converse is not necessarily true." (At least, I could see myself rattling off that fact, if anyone was ever unfortunate enough to have me for a statistics class.)
I've heard this stated enough times, and know it to be true, but have never really worked out an example where the correlation is zero, but the two random variables are not independent. With the proper tools, we disprove the converse with an example.
Suppose we have a mixture of two multivariate Gaussians. That is, we have two blobs, one pointed upward and the other pointed downward. A picture would probably help here:
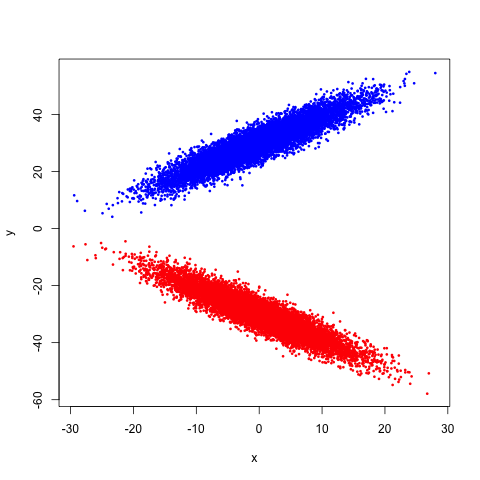
If we try to compute the correlation between \(X\) and \(Y\), we can see geometrically that we should get 0: recalling that for a two dimensional regression, the correlation and the slope of the line of best fit are related by a simple transformation, and noticing that the line of best fit would have a zero slope here2, we get our result3.
But are \(X\) and \(Y\) independent? Clearly not: the more positive \(X\) is, the more likely \(Y\) is to be very large or very small, while the more negative \(X\) is, the more likely \(Y\) is to be near 0. That's a pretty clear dependence, and we can see it. But we don't have to stop at seeing: we can compute!
The quantity we want to compute is the mutual information between \(X\) and \(Y\), which I'll denote as \(I[X; Y]\)4. In particular, two random variables \(X\) and \(Y\) are independent if and only if (we get both directions now) their mutual information is zero. This seems mysterious (how do we get the other direction!) until we recall that the mutual information is the Kullback-Leibler divergence between their joint density and the product of their marginals,
\[ I[X; Y] = \iint\limits_{\mathcal{X}\times\mathcal{Y}} f_{X, Y}(x, y) \log_{2} \frac{f_{X, Y}(x, y)}{f_{X}(x)f_{Y}(y)} \, dA.\]
By inspection, we can see that if \(f_{X, Y}(x,y)\) factors as \(f_{X}(x) f_{Y}(y)\) (which gives us independence), we'll be computing logarithms of 1 throughout, which gives us zero overall for the integral. Thus, mutual information is really measuring how well the joint density factors, which is what we're interested in when it comes to independence.
After writing down the joint density for this data, we could compute the mutual information exactly and show that it's non-zero. Since I'm lazy, I'll let my computer do all of the work via an estimator for the mutual information. The tricky thing about computing information theoretic quantities is that the density itself is the object of interest, since we're computing expectations of it. Fortunately, we have ways of estimating densities5. That is, we can compute kernel density estimates \(\hat{f}_{X}(x)\), \(\hat{f}_{Y}(y)\), and \(\hat{f}_{X, Y}(x, y)\)6, and then plug them into the integral above to give us our 'plug-in' estimator for the mutual information.
Larry Wasserman, John Lafferty, and Han Liu even have a paper on how well we'll do using a method similar to this. I say 'similar' because I'm allowing the R software to automatically choose a bandwidth for the joint density and marginal densities, while they show that to achieve a parametric rate (in terms of the mean-squared error) of \(n^{-1/2}\), we should take \(h \asymp n^{-1/4}\) for both the univariate and bivariate density estimations7. A standard (apparently) result about bivariate density estimation via kernel density estimators is that we should take \(h \asymp n^{-1/6}\) to obtain optimality. Thus, Wasserman et al.'s approach oversmooths compared to what we know should be done for optimal density estimation. But we have to keep in mind that our goal isn't to estimate the density; it's to estimate mutual information. A reminder that how we use our tools depends on the question we're trying to answer.
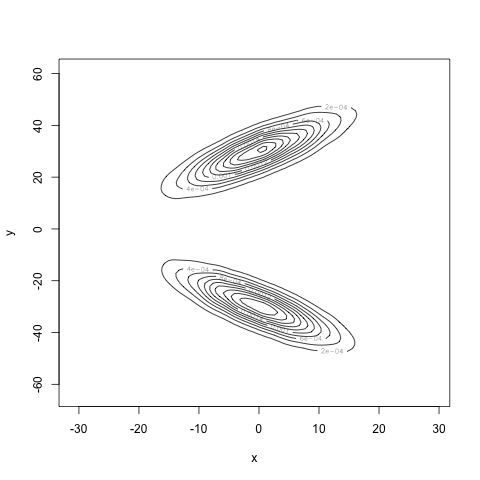
With 10000 samples to estimate the densities, we obtain the following estimator for the joint density:
Computing the marginals and multiplying them together, we see what the density would look like if \(X\) and \(Y\) really were independent:
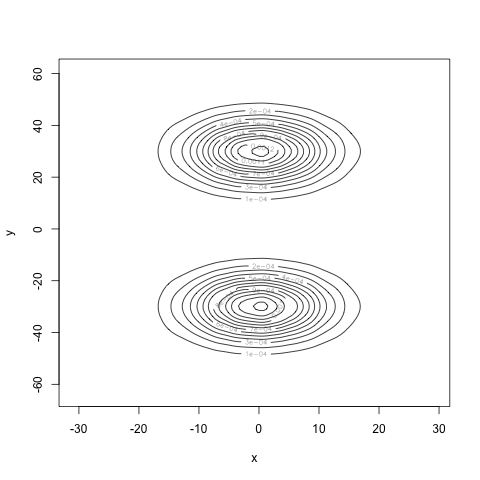
Very different! Finally, our estimate for the mutual information is 0.7, well away from 0. Our estimate for the correlation is 0.004, very close to zero. Our computations agree with our intuition: we have found a density for the pair \((X, Y)\) where \(X\) and \(Y\) are uncorrelated, but certainly not independent.
This exploration of correlation versus independence was originally motivated by a recent paper that made it all the way to a blurb in The Atlantic8. In it, the authors investigate whether properties of a researcher's Wikipedia entry are correlated with their prestige (using things like -index, number of years as a researcher, etc. as a proxy for prestige). They found no correlation. Which makes for a great story. But take a look at some of their evidence:
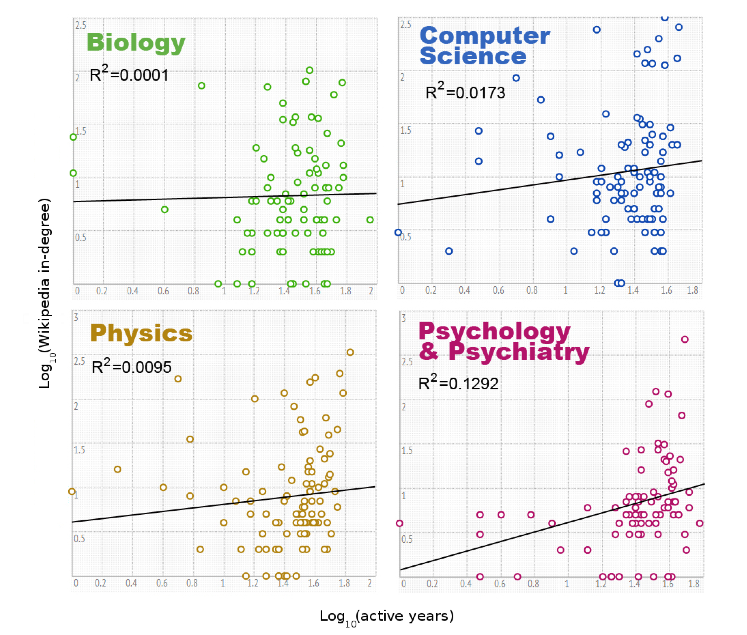
These are plots of the number of active years versus the in-degree of the Wikipedia articles for various authors on a log-log plot because, well, why not? They then fit a line of best fit because, well, that's what you do?9
Nevermind the log-log transformation (which destroys our intuitions about what a correlation would mean) and the fact that we have no reason to believe the expected behavior in the log-log space should be linear. (And never mind the atrocious \(R^{2}\) values, and the fact that we shouldn't be using \(R^{2}\) anyway!). Are the two things really uncorrelated? Its hard to say. But it's even harder to say they're independent, which is really what we'd like to know from the perspective of this study.
I don't expect to hear anyone citing "non-correlation is not independence" anytime soon. But it's something to keep in mind.
Given this fact, a better pneumonic might be "association is not causation."↩
Why? Through the magic of symmetric matrices and eigendecompositions, I've chosen the covariance matrices of each Gaussian to make the blobs exactly cancel each other out.↩
We could also compute out the correlation. But I only have so many integrals left in my life.↩
I sat in on an information theory course taught in our electrical engineering department where the professor used the notation \(I[X \wedge Y]\). I do like that notation, since somehow it seems to more directly indicate the symmetric nature of mutual information. But I digress.↩
Though so so many scientists apparently don't know this. I've recently seen a lot of papers where people needlessly used histogram estimators for their densities. And they had a lot of data points. Why? I can only assume ignorance. Which makes me wonder what basic tools I am ignorant of. I spend every day trying to find out.↩
I'll leave it as an exercise why we estimate the marginals separately from the joint, rather than just estimate the joint and then marginalize.↩
Results like these are one of the many, many reasons why I love statistics. (And wish I was better at its theoretical aspects.) Not only do they show that an estimator exists that can achieve a very nice rate, but they also provide the correct bandwidth in order to achieve this rate. (Good) machine learning people provide insights like this too. Everyone else (i.e. 'scientists') attempt a method, see that it sort of works in a few examples, and then call it a day. I very much fall into that class. But I aspire for the precision of the statisticians and machine learners. In their defense, the scientists are probably busier worrying about their science to learn basic non-parametric statistics. But still...↩
Published in EPJ Data Science, whose tag line reads: "The 21st century is currently witnessing the establishment of data-driven science as a complementary approach to the traditional hypothesis-driven method. This (r)evolution accompanying the paradigm shift from reductionism to complex systems sciences has already largely transformed the natural sciences and is about to bring the same changes to the techno-socio-economic sciences, viewed broadly." How many buzz words can they fit in a single mission statement?↩
So this is data science!↩